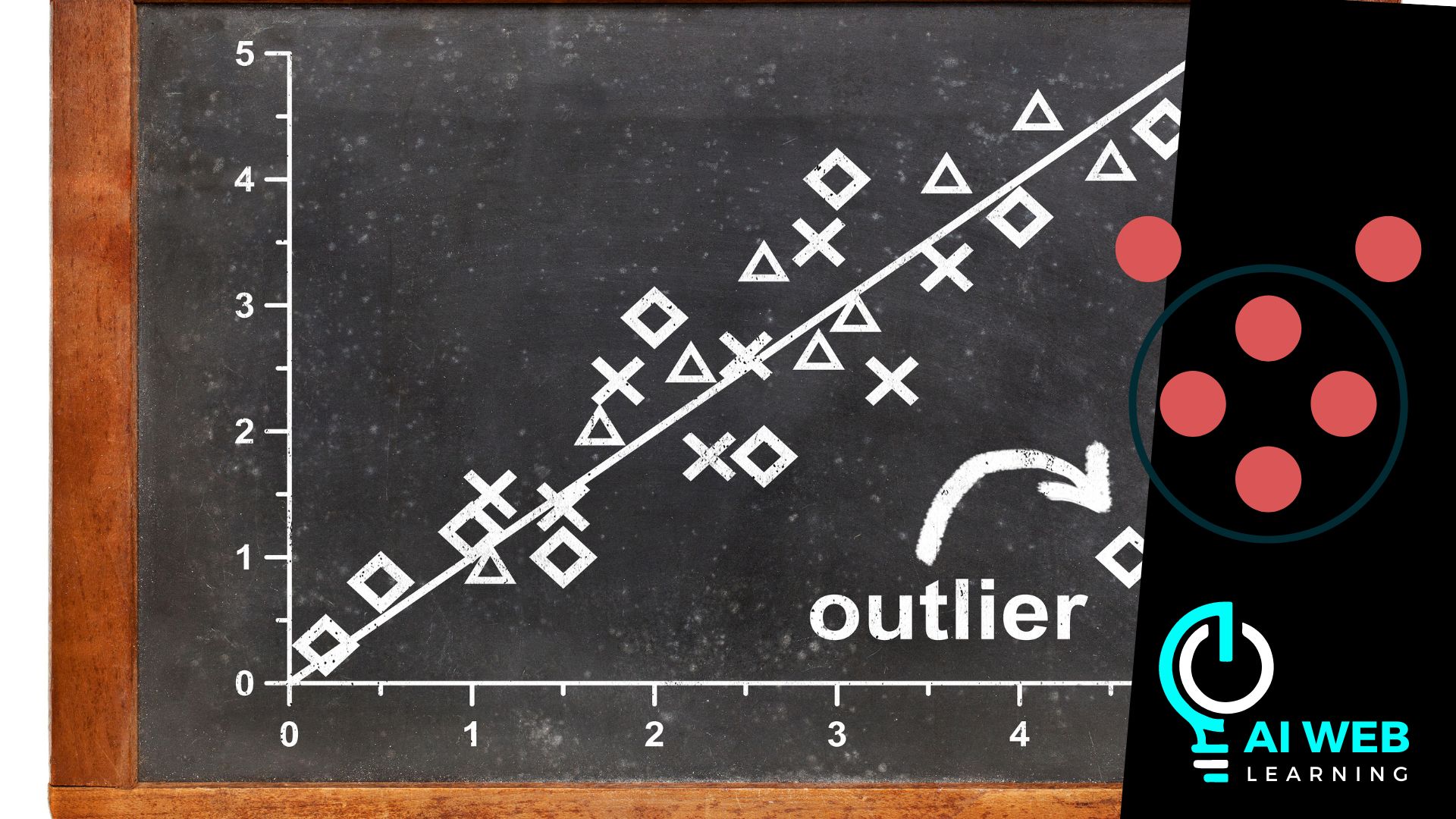
En el mundo del análisis de datos, un «outlier» o valor atípico es un dato que se encuentra significativamente alejado del resto de los datos. Los outliers pueden ofrecer información valiosa o, por el contrario, distorsionar los resultados del análisis si no se manejan adecuadamente. Este artículo explorará qué es un outlier, sus tipos, cómo identificarlos y tratarlos, y su impacto en el análisis de datos.
Definición de Outlier
Un outlier es un valor o una observación que se encuentra muy lejos del conjunto de valores en el que se incluye. Estos valores extremos pueden resultar de variaciones naturales en la población, errores en la medición o la entrada de datos, o pueden indicar fenómenos únicos que merecen una investigación más profunda.
Importancia de los Outliers
Los outliers pueden tener una gran influencia en los resultados de los análisis estadísticos. Dependiendo del contexto, pueden ser:
- Indicadores de errores: Señalando problemas en la recolección o entrada de datos.
- Fenómenos interesantes: Revelando aspectos únicos y dignos de estudio en el conjunto de datos.
- Distorsionadores de resultados: Afectando negativamente los análisis y las conclusiones si no se manejan correctamente.
Tipos de Outliers
1. Outliers Univariados
Estos son valores atípicos que se identifican en un solo conjunto de datos o variable. Por ejemplo, en un conjunto de datos de alturas de personas, una altura de 2.5 metros sería un outlier.
También te puede interesar Hadoop: La Solución Definitiva para el Procesamiento de Grandes Datos
Hadoop: La Solución Definitiva para el Procesamiento de Grandes Datos2. Outliers Multivariados
Estos outliers se identifican cuando se consideran dos o más variables. Un dato puede no ser un outlier en ninguna de las variables por separado, pero en combinación con otras puede resultar atípico. Por ejemplo, en un conjunto de datos de altura y peso, una persona extremadamente alta pero muy ligera podría ser un outlier multivariado.
3. Outliers Globales
Son valores atípicos que se encuentran en todo el conjunto de datos, independientemente del subconjunto que se considere.
4. Outliers Contextuales
Estos valores son atípicos solo en un contexto específico. Por ejemplo, un valor de temperatura de 30°C puede ser normal en verano pero atípico en invierno.
Cómo Identificar Outliers
1. Método Gráfico
Diagramas de Caja (Box Plots)
Un diagrama de caja es una representación gráfica que muestra la distribución de un conjunto de datos y ayuda a identificar outliers. Los valores fuera de los «bigotes» de la caja se consideran outliers.
import matplotlib.pyplot as plt
import numpy as np
data = [10, 12, 12, 14, 14, 14, 15, 16, 16, 18, 19, 19, 20, 25, 29, 33, 45]
plt.boxplot(data)
plt.show()
Gráficos de Dispersión (Scatter Plots)
Los gráficos de dispersión muestran la relación entre dos variables y pueden ayudar a identificar outliers multivariados.
También te puede interesar Optimización y Uso de relevel() en R: Cambia el Nivel de Referencia de Factores
Optimización y Uso de relevel() en R: Cambia el Nivel de Referencia de Factoresimport matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
y = [2, 4, 5, 7, 10, 12, 15, 18, 24, 30, 35, 40, 55, 60, 100]
plt.scatter(x, y)
plt.show()
2. Método Estadístico
Z-Score
El Z-score mide la cantidad de desviaciones estándar que un dato está por encima o por debajo de la media. Valores de Z-score mayores a 3 o menores a -3 suelen considerarse outliers.
import numpy as np
data = [10, 12, 12, 14, 14, 14, 15, 16, 16, 18, 19, 19, 20, 25, 29, 33, 45]
mean = np.mean(data)
std = np.std(data)
z_scores = [(x - mean) / std for x in data]
outliers = [data[i] for i in range(len(data)) if abs(z_scores[i]) > 3]
print(outliers)
IQR (Interquartile Range)
El rango intercuartílico (IQR) se utiliza para identificar outliers. Los datos que se encuentran 1.5 veces el IQR por debajo del primer cuartil o por encima del tercer cuartil se consideran outliers.
import numpy as np
data = [10, 12, 12, 14, 14, 14, 15, 16, 16, 18, 19, 19, 20, 25, 29, 33, 45]
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = [x for x in data if x < lower_bound or x > upper_bound]
print(outliers)
Cómo Tratar los Outliers
1. Eliminación
Eliminar los outliers es una opción cuando se sospecha que estos valores son errores o no son representativos del conjunto de datos. Sin embargo, esta decisión debe tomarse con cuidado para no perder información valiosa.
2. Transformación
Transformar los datos mediante métodos como la normalización o la logaritmización puede reducir el impacto de los outliers.
3. Imputación
Reemplazar los outliers con valores más representativos, como la media o la mediana, puede ser una solución para manejar los outliers sin eliminarlos del conjunto de datos.
También te puede interesar Qué son las series numéricas y cómo clasificarlas
Qué son las series numéricas y cómo clasificarlas4. Uso de Modelos Robustos
Utilizar modelos estadísticos robustos que no se vean afectados significativamente por outliers es otra estrategia. Por ejemplo, la regresión robusta es menos sensible a los outliers que la regresión lineal tradicional.
Impacto de los Outliers en el Análisis de Datos
1. Distorsión de Resultados
Los outliers pueden distorsionar los resultados de los análisis estadísticos, como la media y la varianza, llevando a conclusiones incorrectas.
2. Influencia en Modelos Predictivos
En modelos de machine learning, los outliers pueden afectar negativamente el rendimiento del modelo, especialmente en métodos sensibles como la regresión lineal.
3. Identificación de Fenómenos Únicos
Por otro lado, los outliers pueden indicar fenómenos únicos o inusuales que valen la pena investigar, proporcionando información valiosa sobre el comportamiento de los datos.
Los outliers son un componente crucial en el análisis de datos, que puede ofrecer tanto desafíos como oportunidades. Identificar y tratar los outliers de manera adecuada es esencial para realizar análisis precisos y significativos.
Comprender su naturaleza y el contexto en el que se presentan permitirá a los analistas y científicos de datos tomar decisiones informadas y mejorar la calidad de sus análisis y modelos predictivos.


